The Hidden Surface Algorithm
Now this is the really interesting part of PVRSG. This part will actually determine what polygon is determining the color of a certain pixel, here PVRSG will determine what is visible and what not. The saving of bandwidth is done here.
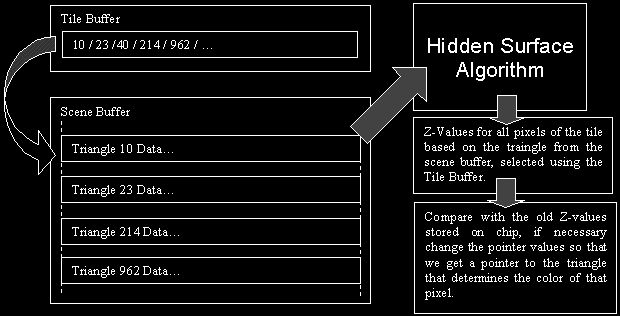
The Hidden Surface Algorithm works on a per Tile (actually microtile) basis. A tile is 32 by 16 pixels. Now the previous step gave us buffers that contain the pointers to the polygons that are located in this tile. This means that one of the polygons in that buffer will determine the color of a certain pixel in that tile. Now the only thing we have to figure out is which of those polygons...
It is not exactly known how PVRSG (or PCX2) solves this problem but the engine doing this works on 32x16 pixels in one go. I think it works like this :
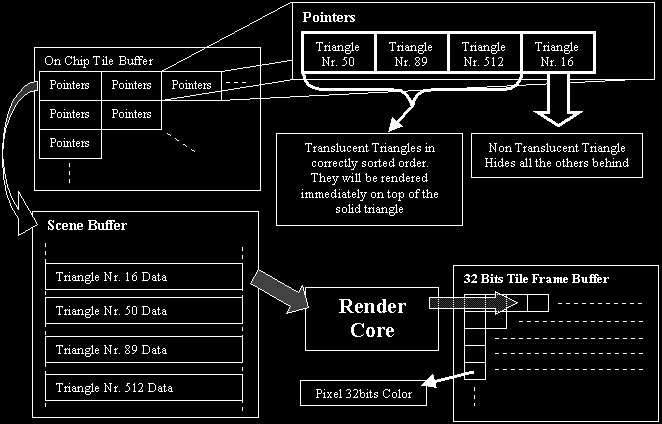
Take the first pointer from the Tile Buffer for this Tile. Based on that pointer you can fetch all the triangle data from the scene buffer (this can be prefetched and placed in a buffer). Using that triangle data you calculate the Z-values (depth values) for every pixel in the tile based on that triangle. So the result of some kind of maths is a tile with Z-values based on that first triangle. these values are stored on chip, together with the pointer to that first triangle. Now we fetch the second pointer from the Tile Buffer for this Tile. Again we get all the triangle data through this pointer from the Scene Buffer. Again we calculate the Z-values for all the pixels of the tile based on the triangle information. Now you compare those new Z-values with the old ones we stored (the values from the first triangle in this case). If the new Z-value is closer to the viewer (thus visible) you update the Z-value and the pointer (pointing to the new visible polygon). If the old value was closer to the viewer nothing is changed. This process is repeated until all polygons from the Tile buffer have been checked. At that moment our on chip buffer contains the pointer to the triangle that will determine the color. if we remember older values we can do pixel perfect transparency (you just make a sorted list of all translucent polygons and the last one is the non-translucent visible one). Now since this Z-calculation is done on 32x16 (=512 pixels) at once the whole thing is very fast.
Now you will probably want to know, is this fast enough?
Well yes. Rendering a tile takes at least 512 clock cycli. So we have 512 clock cycli to do all the sorting. The data fetching can be done in a pipelined structure so there is no penalty for that. The sorting (calculating the Z-values) takes one clockcyclus. The storing an comparing can again be done in a pipelined structure. So it is very probable that every polygon can be checked and the tile updated in one clock cyclus. This means that we can run through 512 triangles per tile before running into trouble. The chance that there are 512 polygons in one tile is very small at the moment. Having 512 polygons in every tile would result in huge amounts of polygons per second : 512 per tile x 600 (for 640x480) = 307200 per frame x 30 fps = 9.2 Million polygons per second ! Normally screen resolution is higher and frame rate too... so the chance that there are 512 triangles in one tile (in a realistic scene) is very small. There will also be no future problems since the parallel processing can be expanded even further.
We also see that this step fits in the pipeline so again the performance hit is invisible, its just some extra latency.
Rendering
Now we can start to render... We will use the information from the previous step : a buffer containing, for each pixel of the to be rendered tile, pointers to the triangle, in the scene buffer, that determines its color and other characteristics. With this information we can render only those pixels visible. There are also per pixel buffers that allow pixel perfect translucency. So basically we take the triangle information from the scene buffer based on the information from the previous step and use that info to render the pixel. The following figure should make this clear:
Transfer to Frame Buffer
The last step is obvious, when the tile is completely rendered it can be transferred to the big frame buffer in graphics memory. In this last move dithering can be done (so only 1 time instead of several times !) or you can do anti-aliasing by down filtering this on chip tile using bicubic filters and storing the result in a lower resolution in the big frame buffer. All these actions are part of the pipeline.
How is this different from the traditional architectures?
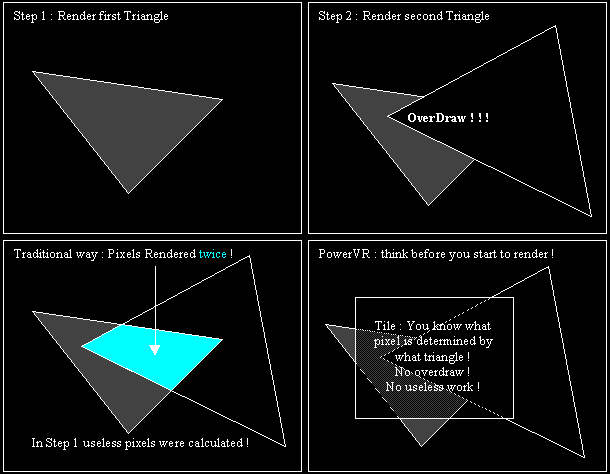
Traditional architectures, like 3Dfx Voodoo2 - Riva TNT and others, work on a per polygon basis. This means that their pipeline will take a triangle render it, take the following triangle and render it, and take again the following triangle and render it,... this means that they do not know what is still to come. PowerVR uses an overview of the scene to decide what to render, traditional renderers just rush into it and do a lot of unnecessary work. The following figure shows this: