Geometry Buffers (G-Buffers)
G-Buffers are 2D images that store geometric details in a texture, storing positions, normals and other details at every pixel. These details are stored so that image space operations can use them as a post-process, originally Takahashi and Saito used these for NPR outlining, hatching etc. But instead we use them as parameters into lighting equations so that we can evaluate a photo-realistic light model after rendering all geometry. To do this we must also store surface material information, this makes our buffers not strictly G-Buffers but I still refer to them as such.
The key ingredient to hardware acceleration of G-Buffers is having the precision to store and process data such as position on a per-pixel basis. This really requires floating point pixel processing (it is possible to do without but this is usually extremely limited), but the higher precision we have to store the G-Buffer at, the slower the hardware renders. Using floats seems tempting from a ease of use point of view but suffers from serious performance problems, the large size (128-bits per 4 channels), slow rendering (up to 4 times slower then 8 bit integers) and other issues (no post-blending operations and limited hardware support under Direct3D) suggests we should attempt to implement G-Buffers without float render-target support.
The element usually requiring the highest precision is the position data, the actual precision required is dependent on which space we store position in. Ideally we want to store our position where quantization errors will minimally affect the lighting.
Storing Position
As we are only storing positions that physically appear on screen we have a finite range that we most cover adequately, this finite range points to a view space or later transform. We want to enclose the view frustum with the minimum bounding box (as this will reduce wastage) but the minimal bounding box to a perspective view frustum is not a good fit, in particular there is a lot of wastage at the near plane. If on the other hand we use the minimal bounding box post-perspective, there is no extra wastage at the near plane. Post-perspective gives us equal number of units across the near and far plane with each unit covering more world space at the far plane[5].
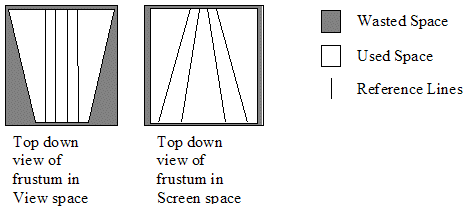
By storing position in screen space (post-perspective, post homogeneous division) we can store our position as a 3D vector that is both compact and high precision over the entire view. This costs a few extra instructions to undo but the advantages in bandwidth and visual fidelity make it worthwhile in my opinion.
Using 16 bit float’s to store view space is another option, the floating point encoding will preserve the precision at both the far and near plane but its still not as accurate as a 16 bit integer screen space position. Using 16 bit float view space will save instructions though, so if the quality is good enough it's probably worth using it [6]. The biggest problem is that rendering to 4 channel float16 formats is not currently widely supported, to support the full range of DirectX 9 hardware I use 16 bit integers as they can be easily stored as 2 sets of 8 bit integers for cards which only have 4 channel 8 bit integer render-targets (currently this affects the NVIDIA GeForce FX).
This leads to a pair of HLSL functions that take HCLIP position and store it in the G-Buffer and the reverse function which produces the position in the space the shader requires (usually for lighting I use view space). The matrix that takes us from screen G-Buffer position into shader space, automatically accounts for the un-bias operation. It also leaves screen space w in place for post-processing effects like fog and depth of field. Other data stored in the G-Buffer may need its own set of pack/unpack functions but most will be a lot less complex than for position data.
| float3 PackPositionForGBuffer( float4 inp ) { float3 o; o.xyz = inp.xyz / inp.w; o.xy = (o.xy * 0.5) + 0.5; return o; } float4 UnPackPositionFromGBuffer( float3 inp ) { float4 o; o.xyzw = mul( float4(inp,1), matGBufferWarp ); o.xyz = o.xyz / o.w; return o; } |
We need enough channels to store all the parameters in our lighting equation, and while every implementation will have different requirements, there are likely to be some parameters required by all.
- Surface Position
- Surface Normal
- Surface Colour
- Surface Material
At a minimum this requires 10 channels and in practise we will use several more. Currently there are no texture formats with that many channels, which implies multiple textures to store all the data. I tend to use 16 channels as this allows enough spare channels to customise the light equation but 12 may be enough in many cases.
The minimum hardware support for G-Buffers is therefore Pixel Shader 2 and render-to-texture. If the hardware only supports 8 bit per channel, any channels that need higher precision will need extra passes and be recombined when used (currently the NVIDIA GeForce FX needs these technique, this may be driver fixable in future).
If the card supports Multiple Render Targets (MRT) (like ATI 9500 and higher), we can use this to reduce the number of passes used to create the G-Buffer. The ATI 9500 and higher cards support up to 4 render-targets simultaneously and each render-target can be an A16B16G16R16 surface so we can generate the G-Buffer used here in 1 pass. Multiple Element Textures may also allow a similar reduction in passes but isn't well supported in hardware yet.
MRT and 16 bit integer render-targets enable single pass G-Buffers to be used as simply as standard rendering, for cards without MRT or higher precision surfaces we have to fall-back to multi-pass techniques to generate the G-Buffer.